
본 글에서는 형태소의 개념과 형태소 라이브러리 및 플러그인에 대한 설명 및 호출방법과 설치방법에 대한 내용을 다룰 것이다. 차례와 사용 툴 및 라이브러리는 아래와 같다.
[차례]
첫 번째, 형태소란
두 번째, 형태소 분석에 알아두면 좋을 용어
세 번째, 형태소 분석에 사용하는 라이브러리 및 플러그인
네 번째, KoNLPY 라이브러리 설치 이전에 유의해야 할 점
다섯 번째, 라이브러리 및 플러그인 설치방법
[사용 툴]
- Jupyter notebook(웹 기반 대화형 코딩 환경)
[사용 라이브러리 및 플러그인]
- KoNLPy(konlpy)
- nltk (punkt, stopwords 플러그인)
- JPype1
- wordcloud
- punkt
형태소
· 형태소란
형태소란 의미를 가진 가장 작은 단위를 말한다. 형태소 분석이란 문장을 이러한 형태소 단위로 분할하는 것을 의미한다. 따라서 문장을 형태소 단위로 분리하면, 그 문장이 전달하는 의미를 좀 더 세밀하게 이해할 수 있다.
예를 들어 "저는 커피를 좋아합니다"라는 문장을 형태소 분석하면 "저/NP", "는/JX", "커피/NNG", "를/JKO", "좋아하/VV". "ㅂ니다/EF"라는 형태로 분석할 수 있다. 여기에서 각각의 약어는 다음과 같은 의미를 가진다. NP(대명사), JX(보조사), NNG(일반명사), JKO(목적격 조사), VV(동사), EF(종결 어미).
형태소 분석은 자연어 처리 분야에서 매우 중요한 역할을 한다. 형태소는 언어의 의미를 가진 가장 작은 단위이기 때문에 효율적인 정보 추출, 언어 이해력 향상 등에 큰 역할을 한다.
예를 들어, 형태소 분석을 통해 문장에서 중요한 키워드를 추출하거나, 특정 형태소가 어떤 품사로 사용되었는지 등의 정보를 알 수 있다. 이는 검색 엔진, 감성 분석 등 다양한 자연어 처리 응용 분야에서 활용된다.
'KoNLPY' 라이브러리는 이러한 형태소 분석을 도와주는 도구이다. 이 라이브러리를 사용하면 한국어 텍스트를 형태소 단위로 쉽게 나눌 수 있다. 이렇게 분석된 데이터는 텍스트의 특성을 파악하거나, 텍스트 데이터를 기계 학습 모델에 입력으로 사용하는 등 다양한 방식으로 활용될 수 있다.
· 형태소 분석에 알아두면 좋을 용어
- 토큰화 : 텍스트 데이터를 '토큰'이라 불리는 작은 단위로 나누는 과정을 의미한다. 예를 들어, 문장을 개별 단어로 나누는 것이 '단어 토큰화'이다. "나는 밥을 먹었다"라는 문장을 단어 토큰화하면 "나는", "밥을", "먹었다"로 나눌 수 있다.
- 품사 태깅 : 각 토큰의 품사를 결정하고 표시하는 과정을 의미한다. 예를 들어, "나는", "밥을", "먹었다" 각 각에 "대명사", "명사", "동사"라는 품사를 태깅하는 것이다.
- 문장 파싱 : 문장의 구조를 분석하는 과정이다. 예를 들어, "나는 밥을 먹었다"라는 문장에서 "나는"이 주어, "밥을"이 목적어, "먹었다"가 동사인 것을 파악하는 것이다.
- 의미론적 추론 : 단어나 문장이 가진 의미를 이해하고, 그를 바탕으로 추론하는 과정이다. 예를 들어, "나는 밥을 먹었다"라는 문장이 의미하는 바는 "나"라는 사람이 "밥"이라는 것을 "먹음"으로서, 이를 통해 "나"가 "밥"을 먹었다는 사실을 추론하는 것이다.
· 형태소 분석에 사용하는 라이브러리
- KoNLPy(konlpy) : 한국어 정보처리를 위한 파이썬 패키지로, 한국어 형태소 분석, 품사 태깅 등을 지원한다. 이를 통해 한국어 텍스트 데이터를 분석하거나, 자연어 처리 과정에서 필요한 전처리 작업을 수행할 수 있다. 'KoNLPy' 라이브러리는 'Hannanum', 'Kkma', 'Komoran', 'Mecab', 'Okt' 등 다양한 형태소 분석기를 포함하고 있다.이를 파이썬에서 사용하려면 다음과 같이 'konlpy'를 Import하여 사용한다.
# (대표적) 한글 형태소 분석기 호출 from konlpy.tag import Oka
- nltk(Natural Language Toolkit) : 자연어 처리와 관련된 여러 가지 기능을 제공하는 오픈 소스 라이브러리이다. 토큰화, 품사 태깅, 문장 파싱, 의미론적 추론 등의 기능을 제공한다. 이를 통해 텍스트 데이터의 분석이나 처리 작업을 수행할 수 있다. 파이썬에서 'nltk'를 사용하려면 다음과 같이 Import하여 사용한다.
# 자연어 처리 라이브러리 호출 import nltk - NLTK 라이브러리의 플러그인 : 'punkt'와 'stopwords'는 NLTK 라이브러리의 플러그인으로, 텍스트 데이터를 처리한다. 'punkt'는 문장이나 단어를 토큰화하는데, 'stopwords'는 분석에 크게 도움이 되지 않는 단어들을 필터링하는 데 사용된다. 파이썬에서 'punkt'와 'stopwords'를 사용하려면 다음과 같이 NLTK 라이브러리에서 Import하여 사용한다.
import nltk # 텍스트 토큰화를 위한 플러그인 호출 nltk.download('punkt') # 불용어 처리를 위한 플러그인 호출 nltk.download('stopwords')
- JPype1 : 파이썬에서 자바 라이브러리를 호출하여 사용할 수 있게 해주는 도구이다. 이를 통해 파이썬 코드 내에서 자바 라이브러리의 기능을 활용할 수 있다. 이를 파이썬에서 사용하려면 다음과 같이 'jpype'를 Import하여 사용한다.
# 형태소 분석 라이브러리 호출 import jpype - wordcloud : 텍스트 데이터에서 가장 많이 등장하는 단어들을 시각적으로 표현하는 워드클라우드를 생성하는 파이썬 라이브러리이다. 형태소 분석을 통해 텍스트에서 중요한 키워드를 추출한 후, 이를 워드클라우드로 표현하면 데이터의 주요 특성을 빠르게 파악하는데 도움이 된다. 즉, 텍스트의 주제나 중요한 내용을 한눈에 보기 쉽게 표현할 수 있다. 따라서 형태소 분석 라이브러리와 함께 'wordcloud' 라이브러리를 설치하면, 텍스트 데이터를 더 깊게 이해하고 분석하는데 유용하다. 이를 파이썬에서 사용하려면 다음과 같이 'WordCloud'를 Import하여 사용한다.
### 워드클라우드 라이브러리 호출 from wordcloud import WordCloud
· KoNLPY 형태소 라이브러리 설치 이전에 유의해야 할 점
'KoNLPy' 라이브러리는 내부적으로 자바(JAVA)로 작성된 형태소 분석기를 사용하기 때문에 자바 환경 설정이 필요하다. 이때 필요한 것이 환경변수 '%JAVA_HOME%'과'%JAVA_HOME%bin'이다.
환경변수는 운영 체제에서 프로그램들이 실행되는 환경을 설정하는 변수를 말한다. 특히, '%JAVA_HOME%'은 자바 JDK(Java Development Kit)의 설치 경로를 가리키는 환경변수이다. 이 변수를 통해 자바 기반의 프로그램이 JDK를 찾아 사용할 수 있게 된다.
'%JAVA_HOME%bin'은 JDK의 'bin' 디렉터리를 가지는 경로이다. 'bin' 디렉터리에는 자바 컴파일러(javac), 자바 실행기(java), 그 외 다양한 자바 관련 도구들이 들어 있다.
따라서, 'KoNLPy'를 사용하기 위해서는 우선 이 두 환경변수를 올바르게 설정해야 한다. 이렇게 설정하면 'KoNLPy'가 자바로 작성된 형태소 분석기를 올바르게 찾아 사용할 수 있게 된다.
1_환경변수 '%JAVA_HOME%', '%JAVA_HOME%bin' 확인
- 내 PC 속성 > 고급 시스템 설정 > 환경변수 > 변수 'Path' 편집 > 위의 두 환경변수가 있는지 확인 (위의 환경변수들이 존재한다면 "3_" 순서를 참고하시면 된다.)
만약, 위의 환경변수들이 존재하지 않는다면 'openjdk'가 지정되어 있는 'Path' 변수에 환경변수를 추가해 주도록 하자.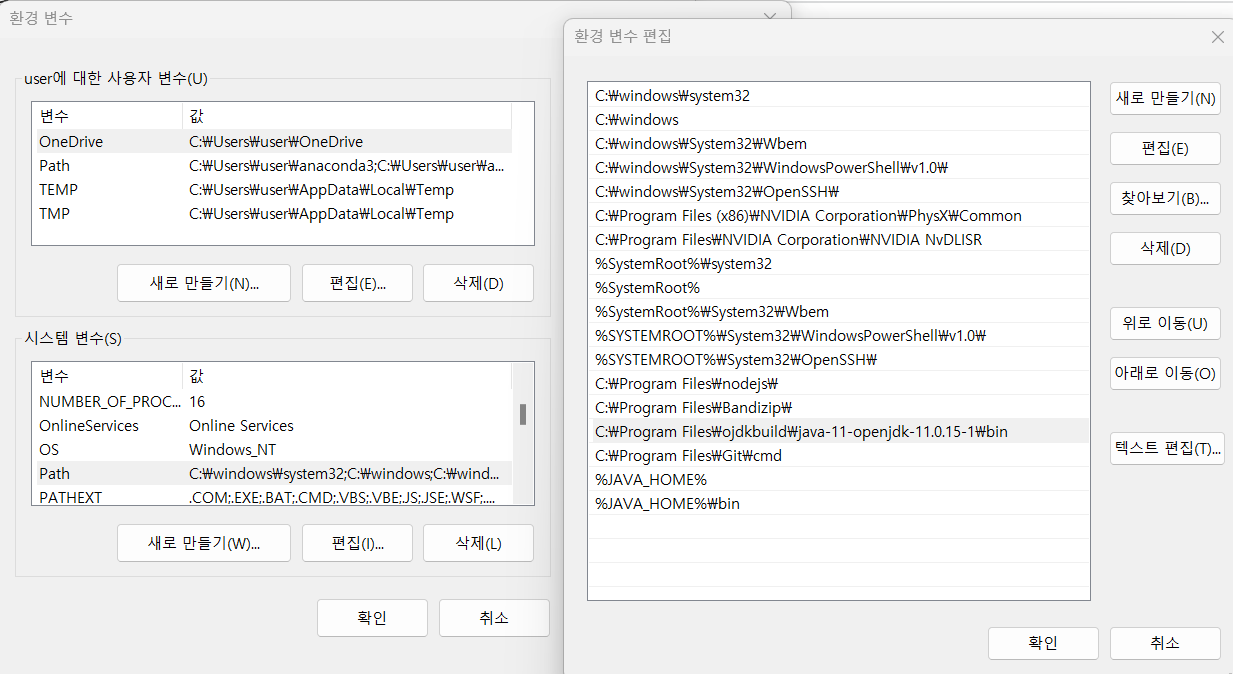
환경변수 확인 '%JAVA_HOME%', '%JAVA_HOME%bin'
2_환경변수 '%JAVA_HOME%', '%JAVA_HOME%bin' 추가
- (위의 절차에 이어) 새로 만들기 > %JAVA_HOME% 생성 | %JAVA_HOME%bin 생성 > 확인 > 시스템 재부팅

환경변수 생성
3_환경변수 '%JAVA_HOME%', '%JAVA_HOME%bin'가 잘 설정되어 있는지 확인하기
- 아나콘타 실행 프롬프트 실행 > javac 입력 | java 입력

아나콘다 실행 프롬프트를 열어 두 환경변수가 잘 설정되어 있는지 확인한다. 확인하는 명령어는 'javac'와 'java'를 각 각 입력한다. 출력된 문자 중, 'help'가 보이면 두 환경변수가 문제없이 잘 설정되어 있음을 나타낸다.
· 각 각의 라이브러리 및 플러그인 설치방법
- nltk 라이브러리 설치
아나콘다 명령 프롬프트 실행 > conda activate 가상환경 > pip install nltk 입력
nltk 라이브러리 설치 - punkt, stopwords 플러그인 설치
아나콘다 명령 프롬프트 실행 > conda activate 가상환경 > python 입력 > import nltk 입력 > nltk.download() 입력 > 'NLTK Downloader' 창 실행 > 'All Packages' 탭 클릭 > punkt Download | stopwords Download > 창 종료 > exit() 입력
단, 마우스 휠로 내려서 다운로드하고자 하는 플러그인을 클릭한 경우에는 인식이 제대로 되지 않을 확률이 높기 때문에, 키보드 ↓ 버튼을 눌러 직접 내려서 선택한 후에 다운로드해주도록 하자.
punkt 라이브러리 다운로드 
stopwords 라이브러리 다운로드 - wordcloud 라이브러리 설치
아나콘다 명령 프롬프트 실행 > conda activate 가상환경 > pip install wordcloud 입력
wordcloud 라이브러리 설치
- JPype1, Konlpy 라이브러리 설치
아나콘다 명령 프롬프트 실행 > conda activate 가상환경 > pip install JPype1 입력 | pip install konlpy 입력
설치 후, 아나콘다 3 폴더 > envs 폴더 > 가상환경 폴더 > Lib 폴더 > site-pakages 폴더 > konlpy 폴더 > 'jvm.py' 파일 메모장으로 열기 > 'foler_suffix' 리스트 내의 별 표시(*) 삭제 후 저장 > 닫기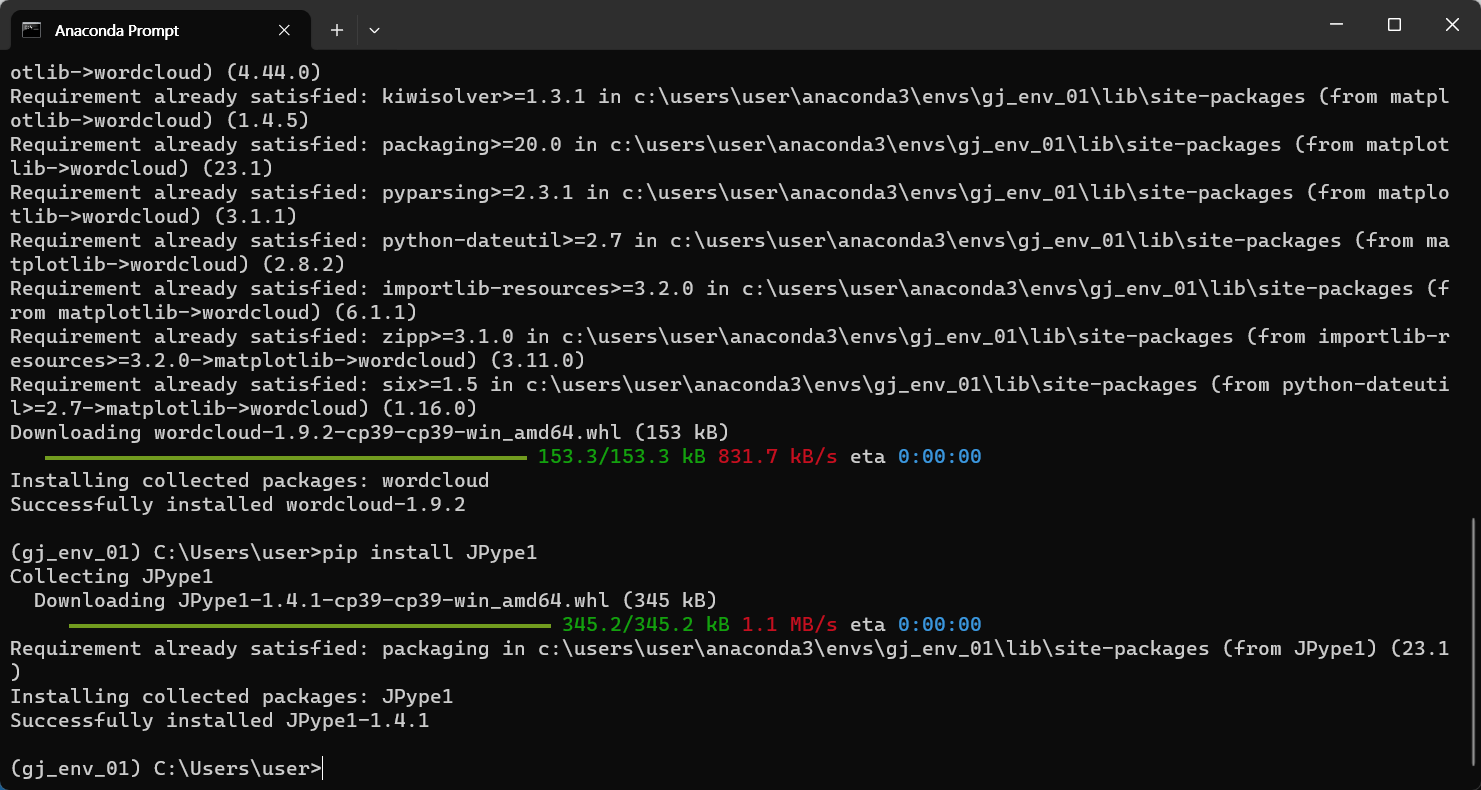
JPype1 라이브러리 설치 
konlpy 라이브러리 설치 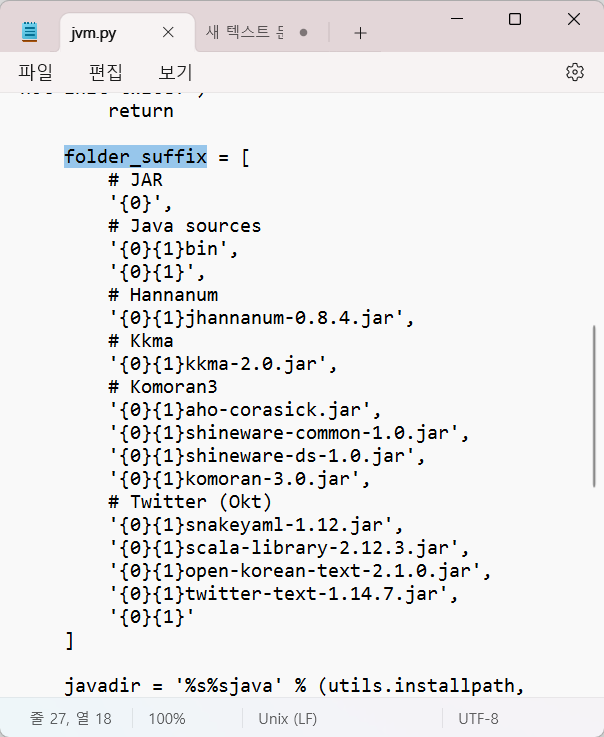
jvm.py 파일 내의 별표시(*) 삭제
'[파이썬] > 데이터 분석' 카테고리의 다른 글
| [데이터 분석] 데이터 빈도분석 및 워드클라우드 시각화 (1) | 2023.12.06 |
|---|---|
| [데이터 분석] selenium 라이브러리를 활용한 동적 웹 크롤링 (3) | 2023.12.05 |
| [데이터 분석] 데이터 시각화를 통한 데이터 분석(matplotlib, matplotlib.pyplot, seaborn) (3) | 2023.12.04 |
| [데이터 분석] 시각화 라이브러리 Matplotlib, Seaborn, matplotlib.pyploy (+폰트 설정, 마이너스 기호 적용) (1) | 2023.12.03 |
| [데이터 분석] 데이터 분석을 위한 데이터 가공(전처리) (4) | 2023.12.03 |



